Los modelos de equilibrio general dinámico estocástico (DSGE) se utilizan en la macroeconomía para modelar el comportamiento conjunto de series de tiempo agregadas, como la inflación, las tasas de interés y el desempleo. A través de esta metodología, se pueden analizar políticas y resolver preguntas como: “Cuál es el efecto de un alza repentina de las tasas de interés sobre el producto?” Para responder esta pregunta, necesitamos un modelo de la relación que hay entre las tasas de interés, la inflación y el producto. A diferencia de otros modelos de múltiples series de tiempo, los modelos DSGE están muy vinculados a la teoría económica. Las teorías macroeconómicas son sistemas de ecuaciones que se surgen de modelar las decisiones de los hogares, las empresas, los hacedores de política, y otros agentes. Estas ecuaciones son los componentes de un modelo DSGE y, puesto que el modelo DSGE surge de la teoría, sus parámetros tienen una interpretación directa en términos de dicha teoría.
En esta entrada, construiremos un pequeño modelo DSGE que es similar a los modelos que se utilizan para el análisis de política monetaria. Mostraremos cómo estimar los parámetros de este modelo utilizando el nuevo comando dsge de Stata 15. Después, aplicaremos un choque al modelo (una contracción de la política monetaria) y graficaremos la respuesta de las demás variables a este choque.
Un pequeño modelo DSGE
Los modelos DSGE comienzan con una descripción de los sectores de la economía que se van a modelar. El modelo que describiremos aquí está relacionado a los modelos que desarrollaron Clarida, Galí, y Gertler (1999) y Woodford (2003). Es una versión más pequeña de los modelos que se utilizan en la banca central y en la academia para hacer análisis de política monetaria. El modelo abarca a tres sectores: hogares, empresas y el banco central.
- Los hogares consumen el producto. Su toma de decisiones está resumida en una ecuación de demanda de producto que relaciona la demanda actual de producto a la demanda futura esperada y a la tasa de interés real.
- Las empresas determinan los precios y generan el producto para satisfacer la demanda a estos precios. Su toma de decisiones se resume en una ecuación de precios que relaciona la inflación actual (es decir, el cambio de los precios) a la inflación futura esperada y a la demanda actual. El parámetro que cuantifica la dependencia entre inflación y demanda tiene un papel clave en este modelo.
- El banco central responde a la inflación determinando la tasa de interés nominal. El banco aumenta la tasa de interés cuando la inflación sube y recorta la tasa cuando la inflación baja.
\begin{align}
x_t &= E_t(x_{t+1}) – \{r_t – E_t(\pi_{t+1}) – z_t\} \\
\pi_t &= \beta E_t(\pi_{t+1}) + \kappa x_t \\
r_t &= \frac{1}{\beta} \pi_t + u_t
\end{align}
La variable \(x_t\) es la brecha del producto. La brecha del producto mide la diferencia entre el producto y su nivel natural de largo plazo. La notación \(E_t(x_{t+1})\) se refiere al valor esperado, dada la información disponible en el periodo \(t\), de la brecha del producto en el periodo \(t+1\). La tasa de interés nominal es \(r_t\), y la tasa de inflación es \(\pi_t\). La Ecuación 1 dice que la brecha del producto actual tiene una relación positiva con la brecha del producto esperada, \(E_t(x_{t+1})\), y una relación inversa con la brecha de la tasa de interés, \(\{r_t – E_t(\pi_{t+1}) – z_t\}\). La segunda ecuación es donde las empresas determinan sus precios; expresa la manera en que la inflación está relacionada con la inflación esperada y la brecha del producto. El parámetro \(\kappa\) determina qué tanto depende la inflación de la brecha del producto. Por último, la tercera ecuación resume el comportamiento del banco central; relaciona la tasa de interés a la inflación y a otros factores, que en conjunto se denominan \(u_t\).
Las variables endógenas \(x_t\), \(\pi_t\), y \(r_t\) son determinadas por dos variables exógenas: \(z_t\) y \(u_t\). Según la teoría, \(z_t\) es la tasa natural de interés. Si la tasa real de interés es igual a la tasa natural y se espera que mantenga ese nivel en el futuro, entonces la brecha del producto es cero. La variable exógena \(u_t\) representa todos los movimientos de la tasa de interés ocasionados por factores que no son la inflación. A veces se denomina el componente sorpresa de la política monetaria.
Aquí modelaremos las dos variables exógenas como procesos autorregresivos de primer orden,
\begin{align}z_{t+1} &= \rho_z z_t + \varepsilon_{t+1} \\
u_{t+1} &= \rho_u u_t + \xi_{t+1}
\end{align}
tal como usualmente se hace.
En la jerga macroeconométrica, las variables endógenas se denominan variables de control, y las exógenas variables de estado. Cada periodo, los valores de las variables de control son determinados por el sistema de ecuaciones. Las variables de control pueden ser observables o no observables. Las variables de estado están fijas al comienzo de un periodo y son no observables. El sistema de ecuaciones determina el valor que tendrán las variables de estado el siguiente periodo.
Nos gustaría usar este modelo para responder preguntas de política. ¿Qué impacto tendrá sobre las variables del modelo si el banco central aumenta su tasa inesperadamente? Podemos responder esta pregunta aplicando un impulso \(\xi_t\) y siguiendo su efecto a través del tiempo.
Antes de cualquier análisis de política, sin embargo, debemos asignar valores a los parámetros del modelo. Estimaremos los parámetros de nuestro modelo con el comando dsge de Stata, utilizando datos estadounidenses de inflación y tasas de interés.
Especificación del DSGE con dsge
En un modelo DSGE, podemos tener tantas variables observables de control como tengamos choques. En nuestro ejemplo, puesto que tenemos dos choques, tenemos dos variables observables de control. Las variables de un modelo DSGE linealizado son estacionarias y se miden en desviaciones del nivel de equilibrio. En la práctica, esto significa que los datos tienen que estar en desviaciones de la media antes de realizar la estimación. El comando dsge calculará estas desviaciones automáticamente.
Utilizaremos la base usmacro2, que se tomó de la Reserva Federal de St. Louis.
. webuse usmacro2
Para especificarle el modelo a Stata, sólo tenemos que ingresar las ecuaciones.
. dsge (x = E(F.x) - (r - E(F.p) - z), unobserved) ///
(p = {beta}*E(F.p) + {kappa}*x) ///
(r = 1/{beta}*p + u) ///
(F.z = {rhoz}*z, state) ///
(F.u = {rhou}*u, state)
Las reglas de este comando son similares a las reglas que rigen a otros comandos de Stata con múltiples expresiones. Cada ecuación se ingresa entre paréntesis. Los parámetros se ingresan con corchetes para distinguirlos de las variables. Los valores esperados de variables futuras aparecen con el operador E(). Sólo una variable aparece del lado izquierdo de cada ecuación. Además, cada variable del modelo aparece del lado izquierdo en sólo una ecuación. Las variables pueden ser observables (variables que están en nuestra base de datos) o no observables. Dado que las variables de estado son fijas en el periodo actual, las ecuaciones de variables de estado nos dicen cómo el valor del periodo inmediato posterior depende del valor actual de las variables de estado y, quizá, del valor actual de las variables de control.
La estimación de los parámetros genera la siguiente tabla de resultados:
. dsge (x = E(F.x) - (r - E(F.p) - z), unobserved) ///
> (p = {beta}*E(F.p) + {kappa}*x) ///
> (r = 1/{beta}*p + u) ///
> (F.z = {rhoz}*z, state) ///
> (F.u = {rhou}*u, state)
(setting technique to bfgs)
Iteration 0: log likelihood = -13738.863
Iteration 1: log likelihood = -1311.9615 (backed up)
Iteration 2: log likelihood = -1024.7903 (backed up)
Iteration 3: log likelihood = -869.19312 (backed up)
Iteration 4: log likelihood = -841.79194 (backed up)
(switching technique to nr)
Iteration 5: log likelihood = -819.0268 (not concave)
Iteration 6: log likelihood = -782.4525 (not concave)
Iteration 7: log likelihood = -764.07067
Iteration 8: log likelihood = -757.85496
Iteration 9: log likelihood = -754.02921
Iteration 10: log likelihood = -753.58072
Iteration 11: log likelihood = -753.57136
Iteration 12: log likelihood = -753.57131
DSGE model
Sample: 1955q1 - 2015q4 Number of obs = 244
Log likelihood = -753.57131
------------------------------------------------------------------------------
| OIM
| Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
/structural |
beta | .514668 .078349 6.57 0.000 .3611067 .6682292
kappa | .1659046 .047407 3.50 0.000 .0729885 .2588207
rhoz | .9545256 .0186424 51.20 0.000 .9179872 .991064
rhou | .7005492 .0452603 15.48 0.000 .6118406 .7892578
-------------+----------------------------------------------------------------
sd(e.z)| .6211208 .1015081 .4221685 .820073
sd(e.u)| 2.3182 .3047433 1.720914 2.915486
------------------------------------------------------------------------------
El parámetro crucial es {kappa}, que según nuestra estimación es positivo. Este parámetro refleja las fricciones de precios que subyacen a nuestro modelo. Su interpretación es que, manteniendo constante la inflación esperada, un aumento de 1 punto porcentual en la brecha del producto está relacionado a un aumento de 0.17 puntos porcentuales en la inflación.
El parámetro \(\beta\) estimado es cercano a 0.5, lo cual significa que el coeficiente de la inflación en la ecuación de tasas de interés es más o menos 2. El banco central entonces aumenta la tasa de interés más o menos 2 puntos porcentuales por cada punto porcentual que aumente la inflación. Este parámetro es muy estudiado en la literatura de economía monetaria, y los estimados rondan 1.5. El valor que estimamos aquí es similar a esos estimados. Por último, nuestra estimación indica que ambas variables de estado \(z_t\) y \(u_t\) son persistentes, con parámetros autorregresivos de 0.95 y 0.7, respectivamente.
Impulsos–respuesta
Ahora podemos utilizar el modelo para responder preguntas de política. Una pregunta que podemos responder es, “¿Qué efecto tendría un movimiento inesperado de tasas sobre la inflación y la brecha del producto?” Un cambio inesperado en la tasa de interés se modela como un choque a la ecuación de \(u_t\). En el lenguaje de nuestro modelo, este choque representa una contracción de la política monetaria.
Un impulso es una serie de valores para el choque \(\xi\) de la Ecuación 5: \((1, 0, 0, 0, 0, \dots)\). El choque entonces se transmite a las variables de estado del modelo, generando un aumento de \(u\). Después, el aumento de \(u\) provoca un cambio en todas las variables de control del modelo. Las funciones de impulso–respuesta siguen el efecto que tiene el choque sobre las variables del modelo, tomando en cuenta todas las relaciones que existen entre las variables.
Ingresaremos tres comandos para obtener y graficar nuestra función de impulso–respuesta (IRF por sus siglas en inglés). El comando irf set define el archivo IRF que contendrá nuestros impulsos–respuesta. El comando irf create genera los impulsos–respuesta en el archivo IRF.
. irf set dsge_irf
. irf create model1
Una vez que nuestros impulsos–respuesta están guardados, podemos graficarlos:. irf graph irf, impulse(u) response(x p r u) byopts(yrescale) yline(0)
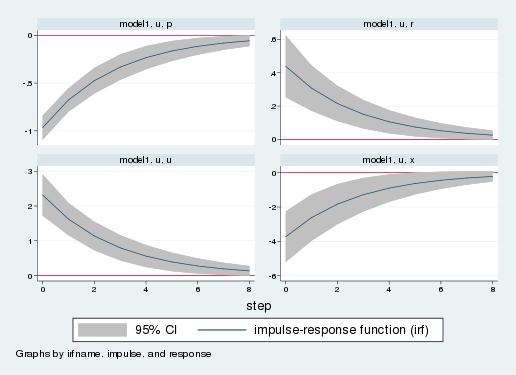
En nuestras gráficas de impulsos–respuesta observamos la respuestas de las variables del modelo a un choque de una desviación estándar. Cada gráfica es la respuesta de una variable a un choque. El eje horizontal indica el tiempo que ha transcurrido desde el choque, mientras que el eje vertical mide las desviaciones del valor de largo plazo. La gráfica de la esquina inferior izquierda muestra la respuesta de la variable de estado monetaria, \(u_t\). Las otras tres gráficas muestran las respuestas de la inflación, la tasa de interés y la brecha del producto. La inflación, en la esquina superior izquierda, observa una caída al momento del choque. La respuesta de la tasa de interés (arriba a la derecha) es una suma ponderada de las respuestas de la inflación y la variable de estado monetaria. La tasa de interés se eleva alrededor de un punto porcentual. Por último, la brecha del producto disminuye. Así, el modelo predice que la economía entra en recesión luego de que ocurre una contracción monetaria. Con el paso del tiempo, el efecto del choque se disipa, y todas las variables regresan a su valor de largo plazo.
Conclusión
En esta entrada, desarrollamos un pequeño modelo DSGE y mostramos cómo estimar sus parámetros utilizando el comando dsge. Luego mostramos cómo obtener e interpretar una función de impulso–respuesta.
Referencias
Clarida, R., J. Galí, y M. Gertler. 1999. The science of monetary policy: A new Keynesian perspective. Journal of Economic Literature 37: 1661–1707.
Woodford, M. 2003. Interest and Prices: Foundations of a Theory of Monetary Policy. Princeton, NJ: Princeton University Press.
Este blog es administrado por MultiON Consulting S.A. de C.V.