Por: Houssein Assaad, Estadístico Senior y Desarrollador de Software.
Este es una traducción realizada por MultiON Consulting de la publicación original de StataCorp.
Tienes un modelo que no es lineal en los parámetros. Tal vez sea un modelo del crecimiento de los árboles y, por tanto, es asintótico a un valor máximo. Tal vez es un modelo de concentraciones séricas de un medicamento que aumenta rápidamente a una concentración máxima y luego decae exponencialmente. Bastante fácil, se usa una regresión no lineal ([R] nl) para ajustar el modelo. Pero… ¿qué pasa si se tienen medidas repetidas para cada árbol o niveles de suero sanguíneo repetidos para cada paciente? Es posible que usted desee explicar la correlación intra árbol o paciente.
El comando menl introducido en Stata 15, ajusta modelos de efectos mixtos no lineales (NLME). Los modelos no lineales clásicos asumen que hay una observación por sujeto y que los sujetos son independientes. Se puede pensar en los modelos NLME como una extensión los modelos no lineales para el caso donde se pueden tomar múltiples medidas sobre un sujeto y estas observaciones intra sujeto están correlacionadas. Asimismo se puede pensar en los modelos NLME como una generalización de los modelos lineales de efectos mixtos donde algunos o todos los efectos aleatorios ingresan al modelo de una forma no lineal. Independientemente de la forma de verlos, los modelos NLME se usan para describir una variable respuesta como una función (no lineal) de las covariables, explicándose la correlación entre observaciones del mismo sujeto.
En este blog, los conduciré a través distintos ejemplos de modelos no lineales de efectos mixtos que se ajustan usando menl. Primero ajustaré un modelo no lineal a los datos sobre el crecimiento de los árboles, ignorando la correlación entre las mediciones del mismo árbol. Luego, demostraré distintas maneras de explicar esta correlación y cómo incorporar efectos aleatorios en los parámetros del modelo para dar a los parámetros la interpretación especifica del árbol.
Tenemos datos (Draper y Smith 1998) sobre la circunferencia del tronco de cinco naranjos diferentes donde se midió la circunferencia del tronco (en mm) en siete ocasiones diferentes, durante un periodo de crecimiento de aproximadamente cuatro años. Queremos modelar el crecimiento de los naranjos. Primero, vamos a graficar los datos.
. webuse orange
. twoway scatter circumf age, connect(L) ylabel(#6)
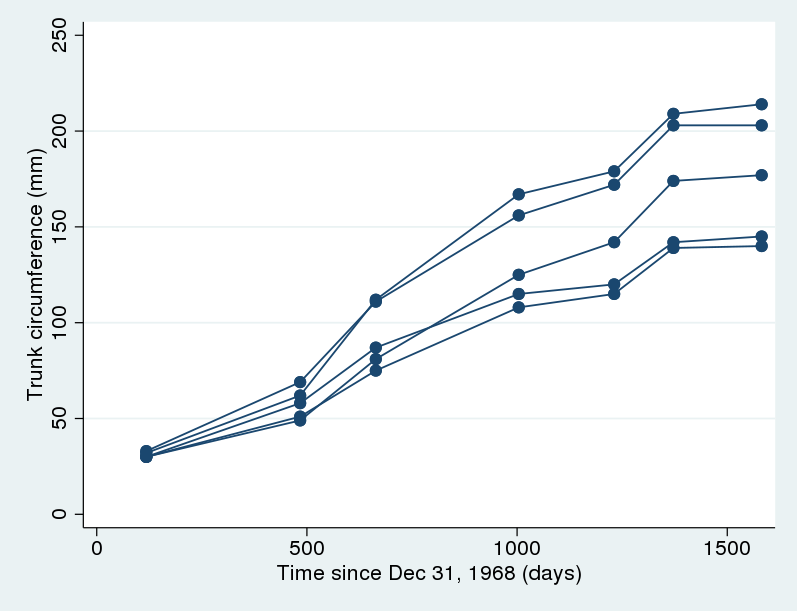
Hay algo de variación en las curvas de crecimiento, pero se observa la misma forma general para todos los árboles. En particular, el crecimiento tiende a nivelarse hacia el final. Pinheiro y Bates (2000) sugieren el siguiente modelo de crecimiento no lineal para estos datos:
\[
{\mathsf{circumf}}_{ij}=\frac{\phi_{1}}{1+\exp\left\{ -\left( {\mathsf{age}}_{ij}-\phi_{2}\right)/\phi_{3}\right\}} + \epsilon_{ij}, \quad j=1,\dots,5; i=1,\dots,7
\]
{\mathsf{circumf}}_{ij}=\frac{\phi_{1}}{1+\exp\left\{ -\left( {\mathsf{age}}_{ij}-\phi_{2}\right)/\phi_{3}\right\}} + \epsilon_{ij}, \quad j=1,\dots,5; i=1,\dots,7
\]
Los parámetros de los modelos NLME a menudo tienen interpretaciones científicamente significativas y forman la base de las preguntas de investigación. En este modelo, \(\phi_{1}\) es la circunferencia asintótica promedio de los árboles mientras \(\mathsf{age}_{ij} \to \infty\), \(\phi_{2}\) es la edad promedio a la cual el árbol alcanza la mitad de la circunferencia asintótica \(\phi_{1}\) (vida media), y \(\phi_{3}\) es un parámetro de escala.
Por ahora, vamos a ignorar las repercusiones (estimaciones menos precisas de la incertidumbre en las estimaciones de los parámetros, pruebas de hipótesis menos potentes, y estimaciones de intervalos menos precisas) de no tener en cuenta la correlación y la posible heterogeneidad entre las observaciones. En su lugar, trataremos todas las observaciones como i.i.d. Podemos usar nl para ajustar el modelo anterior, pero aquí usaremos menl(A partir del 15.1, menl ya no requiere que se incluyan los efectos aleatorios en la especificación del modelo.)
. menl circumf = {phi1}/(1+exp(-(age-{phi2})/{phi3})), stddeviations
Obtaining starting values:
NLS algorithm:
Iteration 0: residual SS = 17480.234
Iteration 1: residual SS = 17480.234
Computing standard errors:
Mixed-effects ML nonlinear regression Number of obs = 35
Log Likelihood = -158.39871
------------------------------------------------------------------------------
circumf | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
/phi1 | 192.6876 20.24411 9.52 0.000 153.0099 232.3653
/phi2 | 728.7564 107.2984 6.79 0.000 518.4555 939.0573
/phi3 | 353.5337 81.47184 4.34 0.000 193.8518 513.2156
------------------------------------------------------------------------------
------------------------------------------------------------------------------
Random-effects Parameters | Estimate Std. Err. [95% Conf. Interval]
-----------------------------+------------------------------------------------
sd(Residual) | 22.34805 2.671102 17.68079 28.24734
------------------------------------------------------------------------------
La opción stddeviations indica a menl que reporte la desviación estándar del término de error en lugar de la varianza. Debido a que una curva de crecimiento se usa para todos los árboles, las diferencias individuales como se muestran en el gráfico anterior se incorporan en los residuales, inflando así la desviación estándar de los residuales.
Tenemos múltiples observaciones del mismo árbol que probablemente estén correlacionadas. Una forma de explicar la dependencia entre observaciones dentro del mismo árbol es incluir un efecto aleatorio, \(u_j\), compartido por todas las observaciones dentro del \(j\)-ésimo árbol. Por lo tanto, nuestro modelo se convierte
$$
\mathsf{circumf}_{ij}=\frac{\phi_{1}}{1+\exp\left\{ -\left( \mathsf{age}_{ij}-\phi_{2}\right)/\phi_{3}\right\}} + u_j + \epsilon_{ij}, \quad j=1,\dots,5; i=1,\dots,7
$$
\mathsf{circumf}_{ij}=\frac{\phi_{1}}{1+\exp\left\{ -\left( \mathsf{age}_{ij}-\phi_{2}\right)/\phi_{3}\right\}} + u_j + \epsilon_{ij}, \quad j=1,\dots,5; i=1,\dots,7
$$
Este modelo puede ajustarse escribiendo
. menl circumf = {phi1}/(1+exp(-(age-{phi2})/{phi3}))+{U[tree]}, stddev
Obtaining starting values by EM:
Alternating PNLS/LME algorithm:
Iteration 1: linearization log likelihood = -147.631786
Iteration 2: linearization log likelihood = -147.631786
Computing standard errors:
Mixed-effects ML nonlinear regression Number of obs = 35
Group variable: tree Number of groups = 5
Obs per group:
min = 7
avg = 7.0
max = 7
Linearization log likelihood = -147.63179
------------------------------------------------------------------------------
circumf | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
/phi1 | 192.2526 17.06127 11.27 0.000 158.8131 225.6921
/phi2 | 729.3642 68.05493 10.72 0.000 595.979 862.7494
/phi3 | 352.405 58.25042 6.05 0.000 238.2363 466.5738
------------------------------------------------------------------------------
------------------------------------------------------------------------------
Random-effects Parameters | Estimate Std. Err. [95% Conf. Interval]
-----------------------------+------------------------------------------------
tree: Identity |
sd(U) | 17.65093 6.065958 8.999985 34.61732
-----------------------------+------------------------------------------------
sd(Residual) | 13.7099 1.76994 10.64497 17.65728
------------------------------------------------------------------------------
Las estimaciones de efectos fijos son similares en ambos modelos, pero sus errores estándar son más pequeños en el modelo anterior. La desviación estándar residual también es menor porque algunas de las diferencias individuales ahora se explican por el efecto aleatorio. Sean \(y_{sj}\) and \(y_{tj}\) dos observaciones del \(j\)j-ésimo árbol. La inclusión del efecto aleatorio \(u_j\) implica que la \({\rm Cov}(y_{sj},y_{tj}) > 0\) (de hecho, es igual a \({\rm Var}(u_j)\)). Por lo tanto, \(u_j\) induce una correlación positiva sobre dos observaciones cualesquiera dentro del mismo árbol.
Hay otra forma de explicar la correlación entre observaciones dentro de un grupo. Puedes modelar la estructura de la covarianza residual explícitamente usando opción rescovariance() de menl. Por ejemplo, el modelo no lineal de intercepto aleatorio anterior es equivalente a un modelo marginal no lineal con una matriz de covarianzas intercambiable. Técnicamente, los dos modelos son equivalentes sólo cuando la correlación de las observaciones dentro del grupo es positiva.
. menl circumf = {phi1}/(1+exp(-(age-{phi2})/{phi3})),
rescovariance(exchangeable, group(tree)) stddev
Obtaining starting values:
Alternating GNLS/ML algorithm:
Iteration 1: log likelihood = -147.632441
Iteration 2: log likelihood = -147.631786
Iteration 3: log likelihood = -147.631786
Iteration 4: log likelihood = -147.631786
Computing standard errors:
Mixed-effects ML nonlinear regression Number of obs = 35
Group variable: tree Number of groups = 5
Obs per group:
min = 7
avg = 7.0
max = 7
Log Likelihood = -147.63179
------------------------------------------------------------------------------
circumf | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
/phi1 | 192.2526 17.06127 11.27 0.000 158.8131 225.6921
/phi2 | 729.3642 68.05493 10.72 0.000 595.979 862.7494
/phi3 | 352.405 58.25042 6.05 0.000 238.2363 466.5738
------------------------------------------------------------------------------
------------------------------------------------------------------------------
Random-effects Parameters | Estimate Std. Err. [95% Conf. Interval]
-----------------------------+------------------------------------------------
Residual: Exchangeable |
sd | 22.34987 4.87771 14.57155 34.28026
corr | .6237137 .1741451 .1707327 .8590478
------------------------------------------------------------------------------
La proporción de efectos fijos de la salida es idéntica en ambos modelos. Estos dos modelos también producen la misma estimación de la matriz de covarianza marginal. Puede verificar esto al ejecutar estat wcorrelation después de cada modelo. Aunque ambos modelos son equivalentes, al incluir un efecto aleatorio en árboles, no podemos sólo explicar la dependencia de las observaciones dentro de los árboles, sino también estimar la variabilidad entre los árboles y predecir los efectos específicos del árbol después de la estimación.
Los dos modelos anteriores implican que las curvas de crecimiento para todos los árboles tienen la misma forma y solo se diferencian por un desplazamiento vertical que es igual a \(u_j\). Esta puede ser una suposición demasiado fuerte en la práctica. Si miramos hacia atrás en el gráfico, notaremos que hay una variabilidad creciente en las circunferencias del tronco de los árboles a medida que se acercan a su altura límite. Por lo tanto, puede ser más razonable permitir que \(\phi_1\) varíe entre árboles. Esto también dará a nuestros parámetros de interés una interpretación específica de árbol. Es decir, asumimos.
$$
\mathsf{circumf}_{ij}=\frac{\phi_{1}}{1+\exp\left\{ -\left( \mathsf{age}_{ij}-\phi_{2}\right)/\phi_{3}\right\}} + \epsilon_{ij}
$$
\mathsf{circumf}_{ij}=\frac{\phi_{1}}{1+\exp\left\{ -\left( \mathsf{age}_{ij}-\phi_{2}\right)/\phi_{3}\right\}} + \epsilon_{ij}
$$
Con
$$
\phi_1 = \phi_{1j} = \beta_1 + u_j
$$
\phi_1 = \phi_{1j} = \beta_1 + u_j
$$
Se puede interpretar \(\beta_1\) como la altura asintótica promedio y \(u_j\) omo una desviación aleatoria del promedio que es especifico del \(j\)-ésimo árbol. El modelo anterior puede ajustarse de la siguiente manera:
. menl circumf = ({b1}+{U1[tree]})/(1+exp(-(age-{phi2})/{phi3}))
Obtaining starting values by EM:
Alternating PNLS/LME algorithm:
Iteration 1: linearization log likelihood = -131.584579
Computing standard errors:
Mixed-effects ML nonlinear regression Number of obs = 35
Group variable: tree Number of groups = 5
Obs per group:
min = 7
avg = 7.0
max = 7
Linearization log likelihood = -131.58458
------------------------------------------------------------------------------
circumf | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
/b1 | 191.049 16.15403 11.83 0.000 159.3877 222.7103
/phi2 | 722.556 35.15082 20.56 0.000 653.6616 791.4503
/phi3 | 344.1624 27.14739 12.68 0.000 290.9545 397.3703
------------------------------------------------------------------------------
------------------------------------------------------------------------------
Random-effects Parameters | Estimate Std. Err. [95% Conf. Interval]
-----------------------------+------------------------------------------------
tree: Identity |
var(U1) | 991.1514 639.4636 279.8776 3510.038
-----------------------------+------------------------------------------------
var(Residual) | 61.56371 15.89568 37.11466 102.1184
------------------------------------------------------------------------------
Si se desea, también podemos modelar la estructura de covarianza del error intra árbol utilizando, por ejemplo, una estructura intercambiable:
. menl circumf = ({b1}+{U1[tree]})/(1+exp(-(age-{phi2})/{phi3})),
rescovariance(exchangeable)
Obtaining starting values by EM:
Alternating PNLS/LME algorithm:
Iteration 1: linearization log likelihood = -131.468559
Iteration 2: linearization log likelihood = -131.470388
Iteration 3: linearization log likelihood = -131.470791
Iteration 4: linearization log likelihood = -131.470813
Iteration 5: linearization log likelihood = -131.470813
Computing standard errors:
Mixed-effects ML nonlinear regression Number of obs = 35
Group variable: tree Number of groups = 5
Obs per group:
min = 7
avg = 7.0
max = 7
Linearization log likelihood = -131.47081
------------------------------------------------------------------------------
circumf | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
/b1 | 191.2005 15.59015 12.26 0.000 160.6444 221.7566
/phi2 | 721.5232 35.66132 20.23 0.000 651.6283 791.4182
/phi3 | 344.3675 27.20839 12.66 0.000 291.0401 397.695
------------------------------------------------------------------------------
------------------------------------------------------------------------------
Random-effects Parameters | Estimate Std. Err. [95% Conf. Interval]
-----------------------------+------------------------------------------------
tree: Identity |
var(U1) | 921.3895 582.735 266.7465 3182.641
-----------------------------+------------------------------------------------
Residual: Exchangeable |
var | 54.85736 14.16704 33.06817 91.00381
cov | -9.142893 2.378124 -13.80393 -4.481856
------------------------------------------------------------------------------
No especificamos la opción group() en el ejemplo pasado porque, en presencia de efectos aleatorios, rescovariance() automáticamente determina el grupo de nivel más bajo en función de los efectos aleatorios especificados.
Los modelos NLME hasta ahora son todos lineales en el efecto aleatorio. En los modelos NLME, los efectos aleatorios pueden ingresar al modelo de forma no lineal, al igual que los efectos fijos, y a menudo lo hacen. Por ejemplo, además de \(\phi_1\), podemos permitir que otros parámetros varíen entre árboles y tener sus propios efectos aleatorios:
. menl circumf = {phi1:}/(1+exp(-(age-{phi2:})/{phi3:})),
define(phi1:{b1}+{U1[tree]})
define(phi2:{b2}+{U2[tree]})
define(phi3:{b3}+{U3[tree]})
(output omitted)
El modelo anterior es muy complicado para nuestros datos que contienen sólo cinco árboles y se incluye únicamente con fines de demostración. Pero a partir de este ejemplo, se puede ver que la opción define() es útil cuando se tiene una expresión no lineal complicada, y se prefiere dividirla en partes más pequeñas. Los parámetros especificados dentro de define() también pueden predecirse para cada árbol después de la estimación. Por ejemplo, una vez que ajustamos nuestro modelo, podemos desear predecir la altura asintótica \(\phi_{1j}\), para cada árbol \(j\). A continuación, solicitamos construir una variable llamada phi1 que contenga los valores predichos para la expresión {phi1:}:
. predict (phi1 = {phi1:})
(output omitted)
Si tuviéramos más árboles, también podríamos haber especificado una estructura de covarianza para estos efectos aleatorios de la siguiente manera:
. menl circumf = {phi1:}/(1+exp(-(age-{phi2:})/{phi3:})),
define(phi1:{b1}+{U1[tree]})
define(phi2:{b2}+{U2[tree]})
define(phi3:{b3}+{U3[tree]})
covariance(U1 U2 U3, unstructured)
(output omitted)
Demostré solo algunos modelos en este artículo, pero menl cpuede hacer mucho más. Por ejemplo, menl cpuede incorporar niveles más altos de anidación, como modelos de tres niveles (por ejemplo, observaciones repetidas anidadas dentro de árboles y árboles anidados dentro de zonas de plantación). Vea [ME] menl para más ejemplos.
Referencias
- Draper, N., and H. Smith. 1998. Applied Regression Analysis. 3rd ed. New York: Wiley.
- Pinheiro, J. C., and D. M. Bates. 2000. Mixed-Effects Models in S and S-PLUS. New York: Springer.
- Draper, N., and H. Smith. 1998. Applied Regression Analysis. 3rd ed. New York: Wiley.
- Pinheiro, J. C., and D. M. Bates. 2000. Mixed-Effects Models in S and S-PLUS. New York: Springer.
Este blog es administrado por MultiON Consulting S.A. de C.V.